Chemins d'accès des utilisateurs - Un modèle basé sur les données

Contenu
Pourquoi des chemins d'utilisateurs ?
Quel est le concept le plus utilisé dans le domaine de l'analyse web ?
Je parie que si vous posez cette question autour de vous, le mot "session" serait l'une des réponses les plus courantes.
Il est universellement reconnu que la session est l'un des concepts clés de l'analyse web et qu'elle est très utile dans une variété d'applications. Cependant, dans certaines situations, nous devons envisager quelque chose de plus général, n'est-ce pas ?
Dans certains cas, nous aimerions analyser les interactions sur des périodes plus longues et à travers de nombreuses sessions. L'attribution marketing est l'un des principaux cas d'utilisation nécessitant une telle approche multi-session. Dans un problème d'attribution, nous analysons les sources de trafic menant à une conversion et évaluons l'impact de chaque source (en d'autres termes, quelles sources étaient essentielles pour cette conversion particulière et lesquelles étaient redondantes).
Pour ce faire, nous devons certainement définir quelles sont les sources à prendre en compte en premier lieu ! Nous devons définir un chemin d'accès de l'utilisateur qui a conduit à la conversion.
L'attribution n'est pas le seul domaine où les parcours utilisateurs sont essentiels. Pensez aux possibilités ! Analyse comportementale... sur plusieurs sessions. Identification des points douloureux... à travers de nombreuses sessions. Il s'agit là d'outils très puissants pour améliorer l'activité de l'entreprise, mais qui nécessitent une étape préliminaire consistant à trouver les chemins d'accès des utilisateurs.
Alors, comment y parvenir en s'appuyant sur des données ? Plongeons dans le vif du sujet !
L'ensemble de données
Nous allons utiliser le modèle de données Google Analytics, car c'est la norme dans le secteur. Nous allons utiliser les données de GA4 car Universal Analytics est de toute façon obsolète.
Nous aurons besoin d'accéder aux données brutes pour voir les paramètres qui sont masqués dans les rapports (comme l'identifiant du client), c'est pourquoi le lien Big Query est indispensable.
Pour illustrer la méthode, nous allons utiliser l'échantillon de données GA4 fourni par Google :
Bien que Google nous prévienne que les données sont obscurcies et que la cohérence interne de l'ensemble de données peut être quelque peu limitée, nous pouvons nous en accommoder pour les besoins de l'illustration.
Mettons-nous au travail et saisissons quelques données ! Tout ce dont nous avons besoin pour l'instant, c'est
- Identifiant unique du client
- Identifiant unique de la session
- Horodatage de chaque début de session
- Label pour les sessions de conversion
Le modèle de données du GA4 est strictement basé sur les événements et la session est plutôt un modèle de données. concept dérivé - malheureusement, cela signifie que nous ne pourrons pas obtenir immédiatement toutes les données dont nous avons besoin - nous devrons travailler un peu plus dur pour cela.
Permettez-moi d'énoncer d'abord la question et d'expliquer les détails ci-dessous :
AVEC TMP AS
(
SELECT
user_pseudo_id,
ep.value.int_value AS session_id,
horodatage de l'événement,
CASE WHEN event_name = 'purchase' THEN 1 ELSE 0 END AS purchase
FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` e,UNNEST(event_params) ep
WHERE
_TABLE_SUFFIX ENTRE '20210101' ET '20210131' AND EP.KEY='GA4_OBFUSCUSED_FAMPLE_ECOMMERCE.EVENTS_*` E
AND ep.key='ga_session_id'
)
SELECT
user_pseudo_id,
session_id,
TIMESTAMP_MICROS(MIN(event_timestamp)) AS session_start,
SUM(purchase) AS transactions
FROM TMP
GROUP BY
user_pseudo_id,
session_id
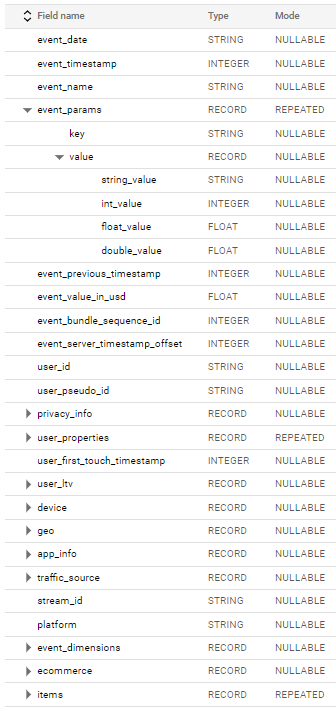
Ainsi, si vous examinez le modèle de données GA4, vous remarquerez que les éléments suivants ont été ajoutés à la base de données user_pseudo_id qui fonctionnera parfaitement en tant qu'identifiant unique du client. L'identifiant de la session, en revanche, est quelque peu caché - il est disponible dans le tableau imbriqué appelé paramètres_événement.
Le tableau contient des paires clé-valeur de tous les paramètres donnés pour un événement particulier - nous recherchons le paramètre valeur_int de la ga_session_id paramètre.
Comme nous travaillons sur des données au niveau de l'événement, nous ne disposons pas de statistiques au niveau de la session - nous devrons les calculer nous-mêmes.
C'est pourquoi nous créons d'abord une table temporaire TMP - nous sélectionnons tous les événements ainsi que leurs horodatages et utilisons une fonction CAS OÙ pour distinguer les événements d'achat représentant des transactions.
Une fois que nous disposons de toutes ces données, nous pouvons résumer la table temporaire en la regroupant par user_pseudo_id et session_id pour obtenir les résultats souhaités au niveau de la session.
Enfin, tenez compte de la condition relative à la _TABLE_SUFFIX dans le fichier OÙ clause. Les données de GA sont stockées dans des tableaux (un pour chaque jour) - cette condition va sélectionner les données de janvier 2021, ce qui donne environ 120'000 sessions - pour les besoins de l'expérience, ce type de volume conviendra ; de plus, le tableau résultant devrait être suffisamment petit pour que vous puissiez l'enregistrer sous forme de fichier CSV local.
Introduction des points d'arrêt (transactions)
Maintenant que nous disposons des données de session, définissons nos chemins d'accès. Pour ce faire, nous trouverons le fichier points de rupture - les moments où un chemin d'utilisateur se termine et un autre commence.
Ce serait magnifique de pouvoir le faire de manière objective et universellement vraie, mais en réalité, cela s'avérerait très difficile, voire impossible. Ce que nous allons faire, c'est créer un modèle sur la base de quelques hypothèses.
Pour trouver notre première hypothèse, reformulons d'abord le problème. Un chemin d'utilisateur est un ensemble de sessions menant à la conversion, n'est-ce pas ? Cela signifie que nous pourrions également l'appeler un processus de conversion. Quand le processus de conversion se termine-t-il ? Lorsque la conversion a lieu, bien sûr !
En réalité, ce n'est pas toujours le cas. Imaginons qu'un client achète un article et revienne une heure plus tard pour acheter un article connexe - dans ce cas, il serait raisonnable d'inclure cette transaction de suivi dans la rubrique précédent chemin d'accès de l'utilisateur.
Mais là encore, un modèle est une simplification de la réalité basée sur certaines hypothèses. Bien que l'on puisse envisager une approche plus nuancée des points de rupture, ce qui donnerait lieu à un modèle plus complexe, nous allons cette fois-ci partir du principe qu'une conversion met définitivement fin à un processus de conversion.
Illustrons cela par un exemple ! Par exemple, regardez la personne avec user_pseudo_id = 27488559.4267170544. Appelons-la Alice pour plus de commodité. Bien sûr, j'utilise Excel, d'ailleurs, pourquoi ne le ferais-je pas ?
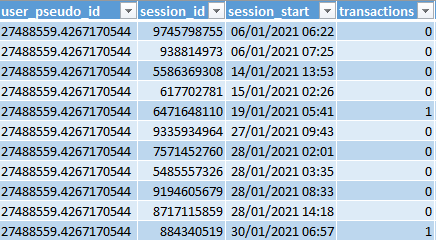
Il y a plusieurs sessions et deux transactions associées à Alice. Représentons cela sur la ligne du temps - puisque nous avons eu deux transactions, il y a deux processus de conversion distincts pour cet utilisateur (j'ai marqué les transactions en orange) :
Les points d'arrêt revisités
Les processus de conversion d'Alice semblent plutôt raisonnables, mais il y a une chose qui pourrait faire lever un sourcil. Les deux sessions du tout début ne correspondent pas tout à fait, n'est-ce pas ?
Voir, beaucoup de temps a passé entre la session numéro 2 et la session numéro 3 - cela fait plus d'une semaine ! Généralement au sein d'un même parcours client ont été plus regroupées. Ne serait-il pas judicieux d'exclure ces premières sessions et de les traiter comme un parcours client entièrement distinct ?
Cette observation nous amène à la deuxième hypothèse clé du modèle. Nous allons supposer qu'une inactivité prolongée met fin au processus de transaction.
Cela soulève une autre question essentielle : quand une période d'inactivité se prolonge-t-elle ? En d'autres termes, comment décider qu'un processus de transaction a échoué en raison de l'inactivité et qu'il doit être abandonné ?
Pour ce faire, nous déterminerons empiriquement la distribution des temps d'attente, puis nous testerons chaque temps d'attente par rapport à cette distribution. Nous dirons qu'un temps d'attente supérieur à un certain quantile de cette distribution met fin au parcours actuel de l'utilisateur. Le choix du point d'arrêt est laissé à notre discrétion - si nous voulons promouvoir des parcours clients plus longs, nous pourrions autoriser des périodes d'inactivité plus longues, et vice versa.
Traçons l'histogramme normalisé des temps d'attente ainsi que quelques quantiles :
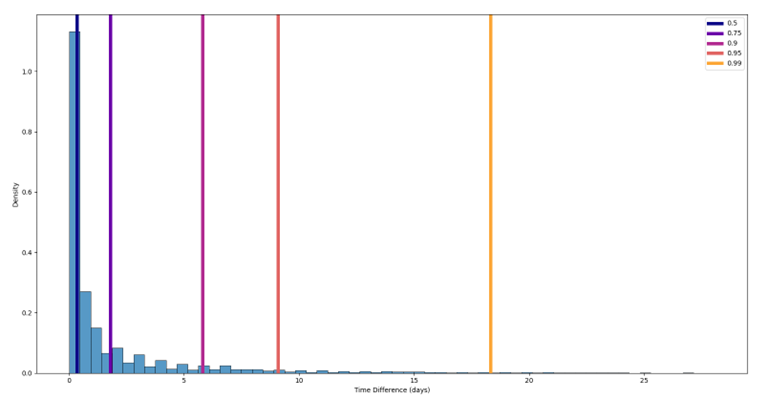
Nous pouvons constater que si un utilisateur revient, c'est le plus souvent au cours des deux premières heures. Par ailleurs, nous avions peut-être raison en ce qui concerne les sessions d'Alice - la probabilité de retour au cours de la première semaine est supérieure à 90%, de sorte que la période d'inactivité entre la deuxième et la troisième session semble un peu excessive.
Incluons les points de rupture dus à l'inactivité dans l'historique des sessions d'Alice ; nous prendrons le quantile 90% comme limite d'inactivité (5,79 jours, pas moins).
Nous pouvons maintenant représenter les sessions d'Alice sur la ligne du temps (les sessions de conversion sont marquées en orange, les inactivités détectées en rouge) :
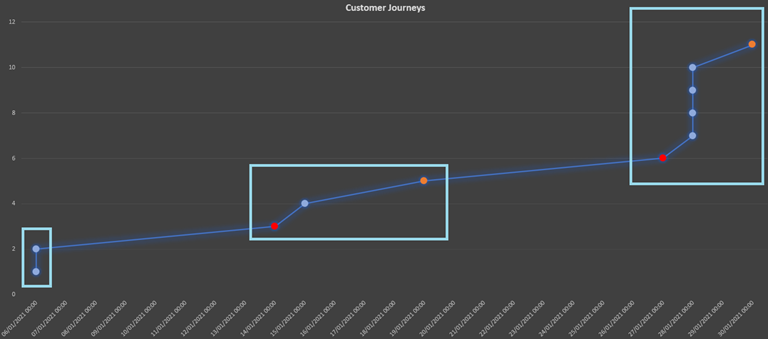
En effet, nous pouvons constater que les deux premières sessions ont été séparées comme prévu !
Notez que les points d'arrêt dus aux transactions sont complètement indépendants des points d'arrêt dus à l'inactivité. En effet, deux points d'arrêt peuvent se produire simultanément - dans ce cas, la session sera orange et rouge en même temps !
Illustrons cela pour les sessions d'Alice. Cette fois-ci, nous allons fixer la limite d'inactivité à 75% quantile (1,79 jours) :
Dans ce cas, la session numéro cinq devient un parcours client isolé en une seule session !
Notez que les points de rupture de différents types affectent les parcours des clients de différentes manières : le point de rupture dû à l'inactivité affecte la session en cours ("si l'inactivité a été détectée, commencer un nouveau parcours utilisateur dès maintenant"), le point de rupture dû à la conversion, en revanche, affecte la session suivante ("si la transaction a été détectée, la prochaine session appartiendra à un nouveau parcours utilisateur"). Veillez à en tenir compte lorsque vous réunissez tous les éléments !
Résumé
Ceci conclut à peu près ce long article de blog, merci d'être resté jusqu'à la fin ! J'espère que vous l'avez trouvé intéressant et instructif (au moins un peu).
À mon avis, le concept de parcours de l'utilisateur est essentiel dans l'analyse moderne du web, car le regroupement des sessions en blocs de construction plus importants constitue l'"étape 0" dans de nombreuses analyses avancées.
Aujourd'hui, nous avons créé un modèle de parcours utilisateur basé sur des données qui prend en compte les schémas comportementaux de nos clients. Nous avons également appris à modifier les paramètres du modèle pour favoriser des processus de conversion plus longs ou plus courts, selon nos préférences.
Maintenant que nous avons terminé l'étape 0, nous pouvons utiliser ces connaissances nouvellement acquises et nous plonger dans des analyses plus approfondies. Par exemple, nous pouvons utiliser nos parcours utilisateurs personnalisés pour construire des modèles d'attribution plus sophistiqués - même une approche simpliste basée sur la position (sans parler des modèles basés sur les données et l'apprentissage automatique) bénéficiera de cette couche de complexité supplémentaire.
Nous pouvons également élargir les analyses comportementales. Nous ne serons plus limités à une seule session ! Au lieu de cela, nous serons en mesure d'analyser les interactions entre toutes les sessions du parcours de l'utilisateur. De cette manière, nous pourrons peut-être identifier les premiers points de douleur susceptibles de faire échouer le processus de conversion.
Nous allons aborder ces sujets plus en détail dans les articles de blog dédiés. A la prochaine fois !