AISO dla bezpieczeństwa marki: jak kontrolować to, co AI mówi o Twojej firmie
Modele językowe stają się nowym źródłem wiedzy i rekomendacji dotyczących marek. Problem w tym, że ich odpowiedzi mogą być niepełne, nieaktualne lub całkowicie błędne, a użytkownicy rzadko weryfikują ich wiarygodność.

Dlatego bezpieczeństwo przekazu w LLM-ach stało się dziś kluczowym wyzwaniem: widoczność jest ważna, ale jeszcze ważniejsze jest zarządzanie ryzykiem związanym z utratą reputacji i i pewność, że AI odzwierciedla przekaz marki w sposób zgodny z faktami. Jak więc kontrolować to, co AI mówi o Twojej marce?
Dlaczego warto kontrolować to, co LLM-y mówią o Twojej marce?
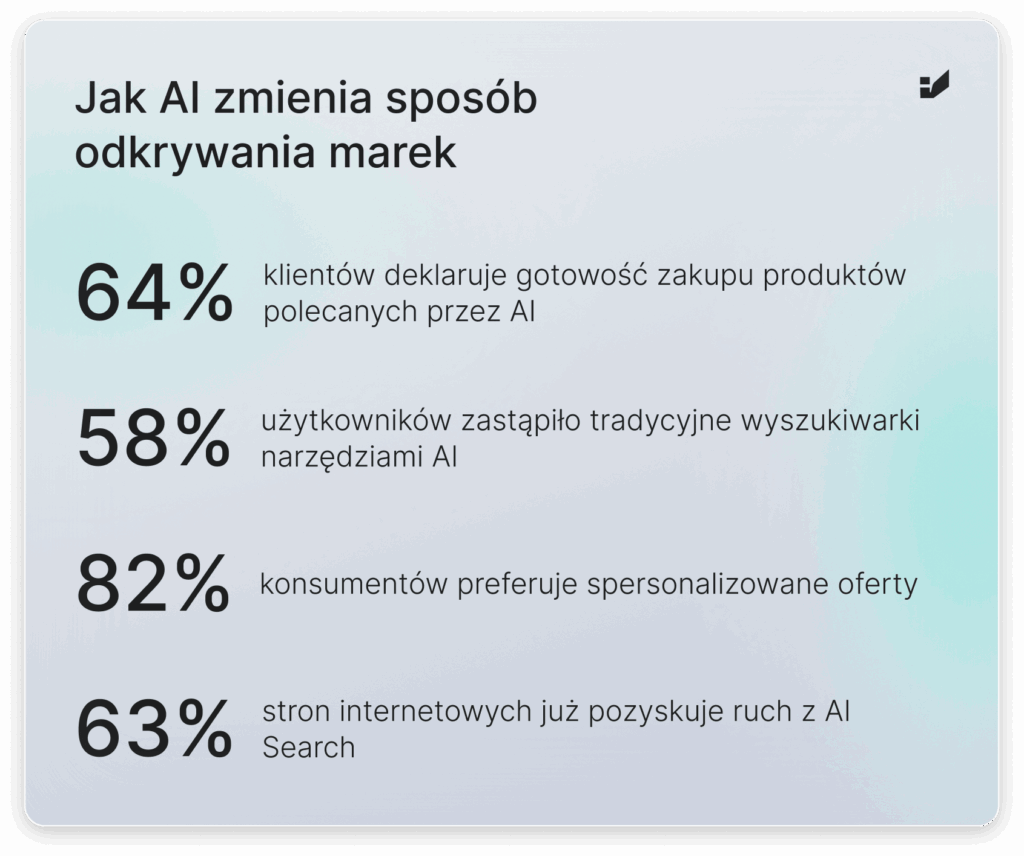
Sposób, w jaki użytkownicy wchodzą w interakcję z informacją się zmienił. Dane jasno pokazują, że AI staje się głównym filtrem, przez który konsumenci odkrywają marki.
- 64% klientów deklaruje gotowość do zakupu produktów rekomendowanych przez AI. Oznacza to, że każda wzmianka o marce w odpowiedzi modelu językowego ma potencjał sprzedażowy porównywalny z bezpośrednią rekomendacją eksperta.
- 58% użytkowników zastąpiło tradycyjne wyszukiwarki narzędziami AI podczas poszukiwania marek i usług. W praktyce dla ponad połowy konsumentów LLM staje się pierwszym punktem kontaktu z rynkiem.
- 82% konsumentów preferuje spersonalizowane oferty, a systemy generatywne potrafią dostarczać je w sposób niedostępny dla tradycyjnych mechanizmów wyszukiwania.
- 63% stron internetowych już pozyskuje ruch z AI Search, co pokazuje, że nie jest to marginalny trend, lecz trwała transformacja ekosystemu widoczności online.
To prowadzi nas do dwóch kluczowych wniosków:
- Jeśli Twoja marka nie pojawia się w odpowiedziach AI, dla części użytkowników po prostu nie istnieje.
- Jeśli natomiast pojawia się, ale w sposób nieaktualny lub niedokładny, ryzykujesz utratą reputacji i wiarygodności.
Kontrolowanie narracji w AI staje się więc strategią niezbędną w budowaniu bezpieczeństwa marki.
Jak chatboty generatywne pozyskują informacje o markach?
Aby skutecznie zarządzać tym, jak modele językowe opisują Twoją markę trzeba zrozumieć, skąd czerpią informacje.
Źródła danych
- Zbiory treningowe: LLM-y są budowane na miliardach tekstów tj. książek, artykułów, blogów, forów, opinii, dokumentacji technicznej oraz treści multimedialnych. To stanowi fundament ich „ogólnej wiedzy”.
- Dane w czasie rzeczywistym: platformy takie jak ChatGPT, Perplexity czy Gemini wzbogacają odpowiedzi o aktualne źródła, takie jak fora (Reddit, Quora), opinie (G2, Capterra, Trustpilot), blogi branżowe czy transkrypcje filmów z YouTube.
- Rekomendacje kontekstowe: ChatGPT w trybie przeglądania lub Microsoft Copilot cytują bezpośrednio strony internetowe pod warunkiem, że są one uznane za wiarygodne.
Mechanizm przetwarzania
LLM-y nie dopasowują jedynie słów kluczowych. Ich celem jest zrozumienie intencji użytkownika i wygenerowanie odpowiedzi, która brzmi naturalnie i kompleksowo obejmuje temat. Proces ten obejmuje:
- analizę semantyczną zapytania oraz rozpoznawanie encji (np. nazw marek, produktów),
- syntezę informacji z wielu źródeł i dobór treści najlepiej dopasowanych do kontekstu,
- generowanie spójnej odpowiedzi, często zawierającej rekomendacje, porównania lub sugestie zakupowe.
Podatność na błędy
Proces ten nie jest wolny od ryzyka. Ponieważ modele opierają się na ogromnych zbiorach danych i nie zawsze weryfikują fakty w czasie rzeczywistym, mogą występować:
- halucynacje – generowanie nieistniejących informacji,
- nieaktualne dane – np. przestarzałe opisy produktów,
- zniekształcenia kontekstowe – mylenie podobnych marek lub usług.
Case study
Sytuacja zniekształcenia kontekstowego miała miejsce w jednym z naszych projektów. Klient z branży telekomunikacji mobilnej, charakteryzujący się spójną komunikacją i wyrazistym tone of voice, był w LLM-ach opisywany zazwyczaj pozytywnie, z jednym wyjątkiem. Jeden z chatbotów, zapytany o opinię na temat marki, często dodawał nieprawdziwą informację, że firma nie posiada infolinii. Komunikat ten pojawiał się mimo, że na stronie klienta infolinia była wyraźnie wyświetlona.
Okazało się, że była to konsekwencja jednej zewnętrznej publikacji zawierającej błędne dane. Choć strona marki i całe jej otoczenie informacyjne potwierdzały istnienie infolinii, model językowy oparł się na jednym wadliwym źródle wprowadzając użytkowników w błąd.
Dlatego kontrolowanie tego, jakie źródła o marce istnieją w internecie i w jakiej formie, staje się kluczowe. Przeczytaj pełne case study tutaj.

Jak kontrolować to, co LLM-y piszą o Twojej marce
Aby zwiększyć kontrolę nad narracją marki w narzędziach AI, potrzebne jest podejście systemowe łączące aspekty contentowe, techniczne i reputacyjne.

Dostarczanie treści, które AI może łatwo wykorzystać
Modele językowe nie wybierają przypadkowych zdań. Preferują te fragmenty tekstu, które są jednoznaczne, uporządkowane i łatwe do cytowania. Dlatego, jeśli marka publikuje treści w przejrzystej strukturze, odpowiada na konkretne pytania i definiuje kluczowe pojęcia, zwiększa szansę, że te źródła zostaną wykorzystane w odpowiedziach. W praktyce przejrzystość formy bezpośrednio przekłada się na to, czy informacje o marce będą przedstawiane poprawnie.
Zarządzanie kontekstem i miejscami, w których wspomniana jest marka
To, co mówią modele, zależy również od tego, skąd pozyskują dane. AI opiera się na artykułach, forach, opiniach i raportach. Jeśli marka jest obecna w rankingach, analizach branżowych lub opiniach użytkowników, jej narracja ma większą szansę na pojawienie się w odpowiedziach. Brak takich wzmianek sprawia, że modele mogą opierać się na przypadkowych, mniej wiarygodnych źródłach, co zwiększa ryzyko zniekształceń.
Wskazywanie priorytetowych treści poprzez plik llm.txt
Coraz większą rolę odgrywają mechanizmy, które pozwalają właścicielom stron kierować modele do odpowiednich zasobów. Plik llm.txt, umieszczony w katalogu głównym domeny, działa jak drogowskaz: informuje, które materiały najlepiej opisują markę i powinny być cytowane w pierwszej kolejności. Pomaga to ograniczyć ryzyko, że modele będą korzystać z nieaktualnych lub przypadkowych źródeł.
Budowanie wiarygodności w oczach modeli (E-E-A-T)
Modele oceniają zarówno treść, jak i jej źródło. Sprawdzają, czy tekst został przygotowany przez osobę z odpowiednią wiedzą, czy odnosi się do badań i danych oraz czy strona ma silną reputację. Publikacje podpisane przez ekspertów, wsparte cytowaniami w źródłach o wysokim autorytecie oraz oznaczone danymi strukturalnymi (np. Article, Person, Organization) są dla AI sygnałem, że treści można zaufać. Zwiększa to znacząco szansę, że narracja marki zostanie uwzględniona w odpowiedziach.
Ciągły monitoring i korekta narracji
Nawet przy najlepszej strategii modele mogą generować błędy. Dlatego kontrola oznacza również regularne sprawdzanie, jak marka jest prezentowana w ChatGPT, Perplexity czy Gemini. W przypadku wykrycia nieścisłości należy zareagować poprzez tworzenie zaktualizowanych treści, publikowanie korekt lub rozbudowanie sekcji FAQ. W ten sposób modele otrzymują poprawne informacje, które z czasem wypierają błędne narracje.

Kolejne kroki w celu ochrony marki w AI
Weszliśmy w nową rzeczywistość w marketingu cyfrowym. Optymalizacja pod AI Search stała się koniecznością ze względu na rosnącą rolę generatywnych modeli językowych w decyzjach konsumenckich.
Marki, które ignorują ten obszar ryzykują utratę widoczności i reputacji. Te, które podejmą działania, zyskają przewagę konkurencyjną stając się naturalnym wyborem rekomendowanym przez systemy AI.
AI zaczyna polecać marki, nie tylko je wyszukiwać. Przejmij kontrolę nad swoją obecnością w AI, zanim zrobią to Twoi konkurenci.



